Contenido:
- Que es distribucion normal
- Distribucion normal de probabilidad
- Probabilidad
- Equivalencia entre probabilidad y conjunto
")
Distribucion normal:
En estadística y probabilidad se llama distribución normal, distribución de Gauss o distribución gaussiana, a una de las distribuciones de probabilidad de variable continua que con más frecuencia aparece aproximada en fenómenos reales.
La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de una función gaussiana.
La importancia de esta distribución radica en que permite modelar numerosos fenómenos naturales, sociales y psicológicos. Mientras que los mecanismos que subyacen a gran parte de este tipo de fenómenos son desconocidos, por la enorme cantidad de variables incontrolables que en ellos intervienen, el uso del modelo normal puede justificarse asumiendo que cada observación se obtiene como la suma de unas pocas causas independientes.
De hecho, la estadística es un modelo matemático que sólo permite describir un fenómeno, sin explicación alguna. Para la explicación causal es preciso el diseño experimental, de ahí que al uso de la estadística en psicología y sociología sea conocido como método correlacional.
La distribución normal también es importante por su relación con la estimación por mínimos cuadrados, uno de los métodos de estimación más simples y antiguos.
Algunos ejemplos de variables asociadas a fenómenos naturales que siguen el modelo de la normal son:
- caracteres morfológicos de individuos como la estatura;
- caracteres fisiológicos como el efecto de un fármaco;
- caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos;
- caracteres psicológicos como el cociente intelectual;
- nivel de ruido en telecomunicaciones;
- errores cometidos al medir ciertas magnitudes;
- etc.
Definición formal
Hay varios modos de definir formalmente una distribución de probabilidad. La forma más visual es mediante su función de densidad. De forma equivalente, también pueden darse para su definición la función de distribución, los momentos, la función característica y la función generatriz de momentos, entre otros.
Función de densidad


Se llama distribución normal "estándar" a aquélla en la que sus parámetros toman los valores μ = 0 y σ = 1. En este caso la función de densidad tiene la siguiente expresión:

Función de distribución



![\Phi(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x}{\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R},](http://upload.wikimedia.org/math/0/4/b/04b42ce6e6eaae4ad68c77d210b9d3ef.png)
![\Phi_{\mu,\sigma^2}(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x-\mu}{\sigma\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R}.](http://upload.wikimedia.org/math/1/0/9/1097cbbb6816a7c2e9ce05bdd0ff09d3.png)
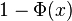 , se denota con frecuencia
, se denota con frecuencia 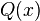 , y es referida, a veces, como simplemente función Q, especialmente en textos de ingeniería.6 7
Esto representa la cola de probabilidad de la distribución gaussiana.
También se usan ocasionalmente otras definiciones de la función Q, las
cuales son todas ellas transformaciones simples de
, y es referida, a veces, como simplemente función Q, especialmente en textos de ingeniería.6 7
Esto representa la cola de probabilidad de la distribución gaussiana.
También se usan ocasionalmente otras definiciones de la función Q, las
cuales son todas ellas transformaciones simples de 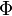 .8
.8La inversa de la función de distribución de la normal estándar (función cuantil) puede expresarse en términos de la inversa de la función de error:


Los valores Φ(x) pueden aproximarse con mucha precisión por distintos métodos, tales como integración numérica, series de Taylor, series asintóticas y fracciones continuas.
Límite inferior y superior estrictos para la función de distribución
Para grandes valores de x la función de distribución de la normal estándar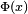 es muy próxima a 1 y
es muy próxima a 1 y  está muy cerca de 0. Los límites elementales
está muy cerca de 0. Los límites elementales
 son útiles.
son útiles.Usando el cambio de variable v = u²/2, el límite superior se obtiene como sigue:

 y la regla del cociente,
y la regla del cociente,
 proporciona el límite inferior.
proporciona el límite inferior.Propiedades
Algunas propiedades de la distribución normal son:- Es simétrica respecto de su media, μ;
 Distribución de probabilidad alrededor de la media en una distribución N(μ, σ).
Distribución de probabilidad alrededor de la media en una distribución N(μ, σ).
- La moda y la mediana son ambas iguales a la media, μ;
- Los puntos de inflexión de la curva se dan para x = μ − σ y x = μ + σ.
- Distribución de probabilidad en un entorno de la media:
- en el intervalo [μ - σ, μ + σ] se encuentra comprendida, aproximadamente, el 68,26% de la distribución;
- en el intervalo [μ - 2σ, μ + 2σ] se encuentra, aproximadamente, el 95,44% de la distribución;
- por su parte, en el intervalo [μ -3σ, μ + 3σ] se encuentra comprendida, aproximadamente, el 99,74% de la distribución. Estas propiedades son de gran utilidad para el establecimiento de intervalos de confianza. Por otra parte, el hecho de que prácticamente la totalidad de la distribución se encuentre a tres desviaciones típicas de la media justifica los límites de las tablas empleadas habitualmente en la normal estándar.
- Si X ~ N(μ, σ2) y a y b son números reales, entonces (aX + b) ~ N(aμ+b, a2σ2).
- Si X ~ N(μx, σx2) e Y ~ N(μy, σy2) son variables aleatorias normales independientes, entonces:
- Su suma está normalmente distribuida con U = X + Y ~ N(μx + μy, σx2 + σy2) (demostración). Recíprocamente, si dos variables aleatorias independientes tienen una suma normalmente distribuida, deben ser normales (Teorema de Crámer).
- Su diferencia está normalmente distribuida con
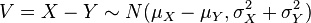 .
. - Si las varianzas de X e Y son iguales, entonces U y V son independientes entre sí.
- La divergencia de Kullback-Leibler,
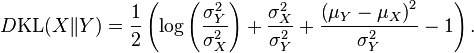
- Si
 e
e 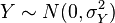 son variables aleatorias independientes normalmente distribuidas, entonces:
son variables aleatorias independientes normalmente distribuidas, entonces:
- Su producto
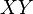 sigue una distribución con densidad
sigue una distribución con densidad  dada por
dada por
 donde
donde  es una función de Bessel modificada de segundo tipo.
es una función de Bessel modificada de segundo tipo.
- Su cociente sigue una distribución de Cauchy con
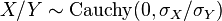 . De este modo la distribución de Cauchy es un tipo especial de distribución cociente.
. De este modo la distribución de Cauchy es un tipo especial de distribución cociente.
- Su producto
- Si
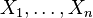 son variables normales estándar independientes, entonces
son variables normales estándar independientes, entonces 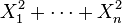 sigue una distribución χ² con n grados de libertad.
sigue una distribución χ² con n grados de libertad. - Si son variables normales estándar independientes, entonces la media muestral
 y la varianza muestral
y la varianza muestral 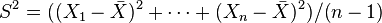 son independientes. Esta propiedad caracteriza a las distribuciones normales y contribuye a explicar por qué el test-F no es robusto respecto a la no-normalidad).
son independientes. Esta propiedad caracteriza a las distribuciones normales y contribuye a explicar por qué el test-F no es robusto respecto a la no-normalidad).

Distribución normal compleja
Considérese la variable aleatoria compleja gaussiana
 . La función de distribución de la variable conjunta es entonces
. La función de distribución de la variable conjunta es entonces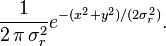
 , la función de distribución resultante para la variable gaussiana compleja Z es
, la función de distribución resultante para la variable gaussiana compleja Z es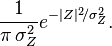
Distribuciones relacionadas
 es una distribución de Rayleigh si
es una distribución de Rayleigh si 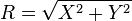 donde
donde  y
y  son dos distribuciones normales independientes.
son dos distribuciones normales independientes.
 es una distribución χ² con
es una distribución χ² con 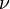 grados de libertad si
grados de libertad si  donde
donde  para
para  y son independientes.
y son independientes.
 es una distribución de Cauchy si
es una distribución de Cauchy si  para
para  y
y  son dos distribuciones normales independientes.
son dos distribuciones normales independientes.
 es una distribución log-normal si
es una distribución log-normal si  y
y 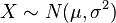 .
.
- Relación con una distribución estable: si
 entonces .
entonces .
- Distribución normal truncada. si
 entonces truncando X por debajo de
entonces truncando X por debajo de  y por encima de
y por encima de  dará lugar a una variable aleatoria de media
dará lugar a una variable aleatoria de media  donde
donde 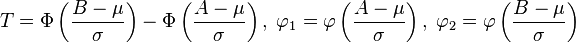 y
y 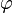 es la función de densidad de una variable normal estándar.
es la función de densidad de una variable normal estándar.
- Si
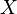 es una variable aleatoria normalmente distribuida e
es una variable aleatoria normalmente distribuida e  , entonces
, entonces  tiene una distribución normal doblada.
tiene una distribución normal doblada.
1. Probabilidad.
La probabilidad p de un suceso está comprendida entre 0 y 1 (0 <= p <= 1), en donde:
p = 0 es la probabilidad del suceso imposible.
p = 1 es la probabilidad del suceso seguro.
2. La distribución normal de probabilidad.
La distribución normal de probabilidad, distribución de Gauss o campana de Gauss es una distribución estadística continua de probabilidad. Se sabe que las características físicas, psicológicas y sociales de una población, además de otros fenómenos, (inteligencia, peso, belleza, longevidad, borreguismo, etc.), siguen más o menos la distribución normal de probabilidad.
Por ejemplo, si la estatura se representa en el eje X, entonces se ve que la mayoría de la gente tiene una estatura normal, situada en el centro de la gráfica, mientras que una minoría de gente es muy alta y otra minoría muy baja, saliéndose de lo normal, según lo mostrado en la gráfica en los extremos izquierdo y derecho. Otro ejemplo es la inteligencia: La mayoría de la gente es de inteligencia normal, mientras que una minoría es muy inteligente y otra es muy poco inteligente. O la longevidad: La mayoría de la gente tiene una esperanza de vida normal, mientras que unos pocos mueren demasiado pronto o llegan a centenarios.
En el eje X se representa una variable estadística y en el eje Y la probabilidad para cada valor de X. Algunas características:
- La media, la mediana y la moda son el valor central en donde la distribución alcanza su valor máximo, siendo una distribución simétrica respecto de este valor. Para valores alejados de la media, decrece exponencialmente.
- El área total bajo la curva del gráfico es 1. Esto es, la integral de la gráfica es 1. O dicho de otra forma, la suma total de todas las probabilidades es 1.
- El gráfico de arriba muestra las principales subáreas del gráfico.
- La probabilidad de que x sea cualquier valor <= x1 (donde x1 es un valor cualquiera de X), es la integral de la curva hasta x1, o sea, el área bajo la curva hasta x1, o lo que es lo mismo, la suma de todas las probabilidades hasta x1:
")
3. Equivalencia entre probabilidades y conjuntos.
Hay una equivalencia en operar con probabilidades y operar con conjuntos, debido a que ambas cosas siguen el álgebra de Boole.
a) Operar con conjuntos.
El conjunto total es el conjunto formado por todos los elementos, del que se obtienen subconjuntos. El conjunto vacío es el conjunto sin ningún elemento.
Si tenemos por ejemplo un conjunto formado por las mujeres muy inteligentes y otro formado por las mujeres muy atractivas, (ambos conjuntos pequeños, tal y como sugieren las respectivas distribuciones normales de probabilidad), entonces el subconjunto formado por las mujeres muy inteligentes que son además muy atractivas será la intersección de ambos conjuntos, y este subconjunto intersección será de un tamaño menor o como mucho igual que los conjuntos de mujeres atractivas y de mujeres inteligentes por separado, pues es obvio que si es difícil encontrar a una atractiva, más difícil es encontrar a una que sea además inteligente.
Por el contrario, si se quiere encontrar a una que sea inteligente o que sea atractiva (no necesariamente las dos cosas, sino solamente una de ellas), será la unión de los dos conjuntos, resultando en un conjunto mayor.
Por último, el conjunto complemento de un subconjunto A es el conjunto que no contiene ningún elemento de A: Conjunto total – A.
b) Operar numéricamente con probabilidades.
La probabilidad del suceso seguro es 1 y es equivalente al conjunto total. La del suceso imposible es 0 y es equivalente al conjunto vacío.
Esta operación de intersección de conjuntos se expresa numéricamente en términos de probabilidades como el producto de las probabilidades. Como la probabilidad de un suceso es un número menor o igual que 1, el producto de dos probabilidades “p”, “q”, va a ser menor o igual que 1 también, y menor o igual que “p” y que “q”.
En el ejemplo anterior, supongamos que la probabilidad de encontrar a una mujer atractiva es p=0’20 y la de encontrar a una inteligente es q=0’25. Entonces, la probabilidad de encontrar a una que sea inteligente y atractiva es p·q = 0’20 x 0’25 = 0’05, mucho más pequeña que la de encontrar a una que sólo sea atractiva/inteligente:
p·q <= p
p·q <= q
Por el contrario, la probabilidad de encontrar una mujer que sea o inteligente o atractiva será la suma de probabilidades p+q = 0’45:
p+q >= p
p+q >= q
Por último, la probabilidad del complemento de p (el conjunto que no tiene elementos en p) es 1-p: restar la probabilidad de p a la probabilidad del suceso seguro que es 1.
Resumiendo las operaciones del álgebra de Boole con sus equivalentes numéricos de probabilidad y de conjuntos:
- Producto lógico = Intersección de conjuntos = producto de probabilidades.
- Suma lógica = Unión de conjuntos = suma de probabilidades.
- Complemento = Conjunto total – subconjunto = 1 – p